
Tech Showcase: Invertible Neural Networks on MNIST
In the race to develop increasingly powerful artificial intelligence systems, we've created models that can recognize objects in images, translate languages, and even generate human-like text. However, this remarkable progress has come with a significant trade-off: as neural networks have grown more complex, they've also become more opaque in their decision-making processes. At Transparent AI, we're tackling this challenge head-on with invertible neural networks—a promising approach that could fundamentally change how we understand AI systems.
The Black Box Problem
Traditional neural networks suffer from what's commonly called the "black box problem." These models transform input data through multiple layers of non-linear operations, effectively destroying information along the way. While they can achieve impressive accuracy, they offer little insight into why they made a particular decision or how they arrived at a specific output.
This opacity creates several critical problems:
Regulatory compliance becomes challenging in sectors like healthcare, finance, and criminal justice, where explanations for decisions are often legally required
Trust issues emerge when users can't understand how decisions affecting them were made
Debugging and improvement become more difficult without clear insights into failure modes
Bias detection is hampered when we can't trace how input features influence outcomes
Post-hoc explanation methods like LIME and SHAP attempt to address these issues, but they're approximations at best and can add significant computational overhead—often increasing energy consumption by 5x or more for a single prediction.
Enter Invertible Neural Networks
Invertible Neural Networks (INNs) offer a fundamentally different approach. Unlike traditional networks, INNs are designed with a crucial mathematical property: bijective mapping. This means there's a one-to-one correspondence between inputs and outputs, allowing the network to be run in reverse.
The key advantage? No information is lost during processing. Every output from an INN can be mapped back perfectly to its original input.
This property transforms how we approach explainability:
Rather than approximating explanations after the fact, we can directly trace the network's decision-making process
We can identify exactly which input features contributed to a particular classification
We maintain perfect information flow in both directions through the network
Our MNIST Classification Demo
To demonstrate the power of this approach, we built an invertible neural network for the classic MNIST handwritten digit classification task. While MNIST might seem simple, it provides an ideal testing ground for visualizing and understanding how INNs work.
Architecture and Implementation
Our implementation uses:
PyTorch as the base deep learning framework
FrEIA (Framework for Easily Invertible Architectures) to handle the invertible components
A combination of GLOWCouplingBlock and PermuteRandom modules to maintain invertibility
The network architecture consists of:
An invertible network that transforms the input image (784 pixels) into a latent representation
A classifier head that maps from this latent space to digit predictions
Visualization components that leverage the invertibility to show attribution
Results: Accuracy with Transparency
Our model achieved impressive results:
99.49% accuracy on the training set
97.55% accuracy on the test set
This performance places it at rank 37 on the PapersWithCode MNIST benchmark rankings, competitive with many specialized approaches. But the real breakthrough isn't the accuracy—it's the combination of high performance with complete transparency.
Perfect Reconstruction: Nothing Is Lost
When we ran invertibility tests on our model, we found reconstruction errors as high as 0.000002—effectively zero. This means our network can perfectly reconstruct its inputs, confirming that no information is lost during processing.

The original image (left), transformed representation (middle), and reconstructed image (right) showing perfect reconstruction
The middle image showing the transformed feature representation appears as seemingly random colored pixels—and that's exactly what we want to see. This indicates the network has learned to distribute information across the entire latent space rather than simply copying the input. Despite this complex transformation, the model can still perfectly reconstruct the original input.
Attribution: Where Is The Model Looking?
One of the most powerful capabilities of our invertible approach is the ability to visualize exactly which pixels contributed to a classification decision.
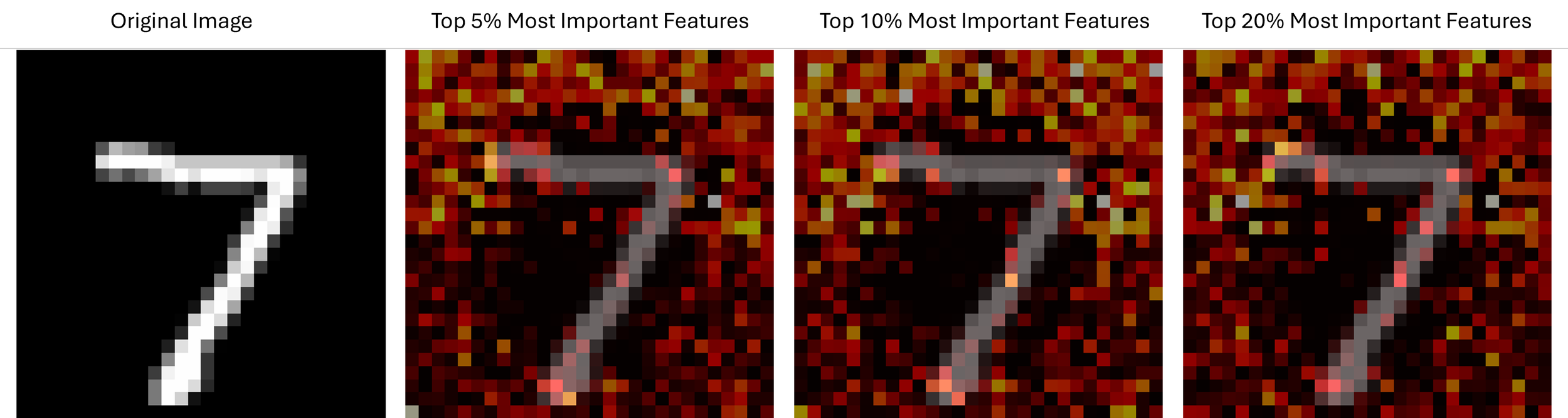
Attribution visualization showing which pixels most strongly influenced the classification
In these visualizations:
Yellow/white areas show pixels with the highest importance to the classification
Red areas indicate medium importance
Dark/black areas show lower importance or no contribution
We created visualizations at three different sparsity levels (5%, 10%, and 20% of the most important features) to show how the network's attention progressively expands from the most critical pixels to supporting features.
Unlike post-hoc attribution methods, these visualizations directly leverage the invertibility of the network to show exactly which input features influenced the decision—there's no approximation or guesswork involved.
Learning from Mistakes
Perhaps the most valuable insight comes from analyzing cases where the model gets things wrong. By examining misclassified digits, we can see exactly what confused the model:

Analysis of a misclassified digit, showing which features led to the incorrect prediction
This provides unprecedented visibility into failure modes. We can see, for instance, when a messy "9" is classified as a "5" because the loop of the '“9” is not closed, making it resemble a “5”.
This level of insight is simply not available with conventional neural networks without significant additional computational overhead.
Benefits Beyond Explainability
The advantages of invertible neural networks extend well beyond mere transparency:
Energy Efficiency: No need for computationally expensive post-hoc explanations like LIME or SHAP, which can add 5x the energy consumption
True Auditability: Every decision can be traced back to specific input features with mathematical certainty
Enhanced Trust: Users can verify exactly how their data influenced the outcome
Improved Debugging: Engineers can pinpoint exactly what's causing incorrect classifications
Better Model Development: Insights from attribution can guide more focused improvements
The Road Ahead
While this MNIST demo serves as a proof-of-concept, the implications for more complex applications are substantial. At Transparent AI, we're already exploring applications in:
Medical image analysis, where doctors need to understand exactly what triggered a diagnosis
Financial decision-making, where regulators require explanations for loan approvals or denials
Autonomous systems, where safety-critical decisions must be fully auditable
Content moderation, where transparency in decision-making is essential for fairness
Invertible neural networks represent a fundamental shift in how we approach AI explainability—moving from post-hoc approximations to intrinsic transparency built into the very architecture of our models.
As we continue to develop and refine these approaches, we're excited about the potential to build AI systems that are not only powerful but also understandable, auditable, and trustworthy.